


Harness Engineering,再到 Trellis 落地实战
0. 写在前面
过去一年,AI 编程工具的发展速度远超预期。从 Claude Code 到 Agent Teams,从 Skills 到 MCP,工具能力在快速膨胀。
但一个尴尬的现实是:工具越强,乱象越多。
几个典型场景,估计你也不陌生:
- 开了一个 Claude Code 会话,聊了 200 轮,上下文塞满了中间分析、报错日志、废弃方案,最后连自己在做什么都看不清了;
- 换了一个新会话继续干活,结果 AI 完全不知道之前约定好的编码规范、目录结构、接口契约,每次都要重新”教育”一遍;
- 三个 Agent 并行干活,没人协调边界,最终合并时发现改了同一个文件,冲突一堆;
- Bug 修了三次还在反复,因为每次修复都没有沉淀成经验,下一次换个 Agent 照样踩坑。
这些问题本质上不是模型能力不够,而是缺乏一套系统性的”驾驭框架”(Harness)。
这篇文章要讲的就是这个主题——从 Harness Engineering 的理念出发,到 Trellis 这个具体落地框架的完整实战。主要分三部分:
- Harness Engineering 是什么,以及为什么 Anthropic 把它当作 AI Coding 的核心哲学
- Trellis 是怎么把 Harness 理念落地的,包括 Spec 系统、Task 工作流、JSONL 上下文注入
- 真实的落地实战,从项目初始化到完成一个完整需求的六阶段全流程
1. 一句话总结
Harness Engineering 的本质,是把”AI 不知道的东西”结构化地告诉它。 而 Trellis 做的事情,是把这个理念变成一套可复现、可沉淀、可协作的工程框架——它不是给你一个更强的模型,而是给你一套让模型表现更稳定的”操作系统”。
2. 什么是 Harness Engineering
2.1 核心哲学
Anthropic 在描述 Claude Code 的设计哲学时,有一句非常关键的话:
Every component in a harness encodes an assumption about what the model can’t do on its own, and those assumptions are worth stress testing, both because they may be incorrect, and because they can quickly go stale as models improve.
翻译过来就是:Harness(驾驭框架)中的每一个组件,本质上都编码了一个关于”模型自己搞不定什么”的假设。这些假设值得反复验证——因为它们可能是错的,也因为模型能力在快速进化。
这句话点出了 Harness Engineering 的三个核心洞察:

说白了,Harness Engineering 不是让你写更长的 Prompt,而是让你把模型缺失的上下文、规范、流程、经验,系统性地管理起来。它不是银弹,而是一套工程方法论。
2.2 为什么现在需要 Harness
AI Coding 工具的发展大致经历了三个阶段:
| 阶段 | 代表工具 | 交互模式 | 核心局限 |
|---|---|---|---|
| 代码补全 | GitHub Copilot | Tab 补全 | 只能补片段,没有全局视野 |
| 会话式开发 | Claude Code、Cursor | 对话驱动 | 会话一长就乱,跨会话失忆 |
| 多智能体协作 | Agent Teams、Trellis | 团队协作 | 协调成本高,需要更强的治理框架 |
每升一级,对 Harness 的需求就大一圈:
- 代码补全阶段:你只需要告诉 AI “这里补一行”;
- 会话式开发阶段:你需要让 AI 理解整个项目的架构、规范和历史;
- 多智能体阶段:你还需要协调多个 AI 的分工、边界、依赖和结果汇总。
阶段越高,Harness 越重要。
3. Harness 层工具生态
在 Trellis 之前,社区已经探索出了几个重要的 Harness 层工具。理解它们,才能理解 Trellis 为什么这样设计。
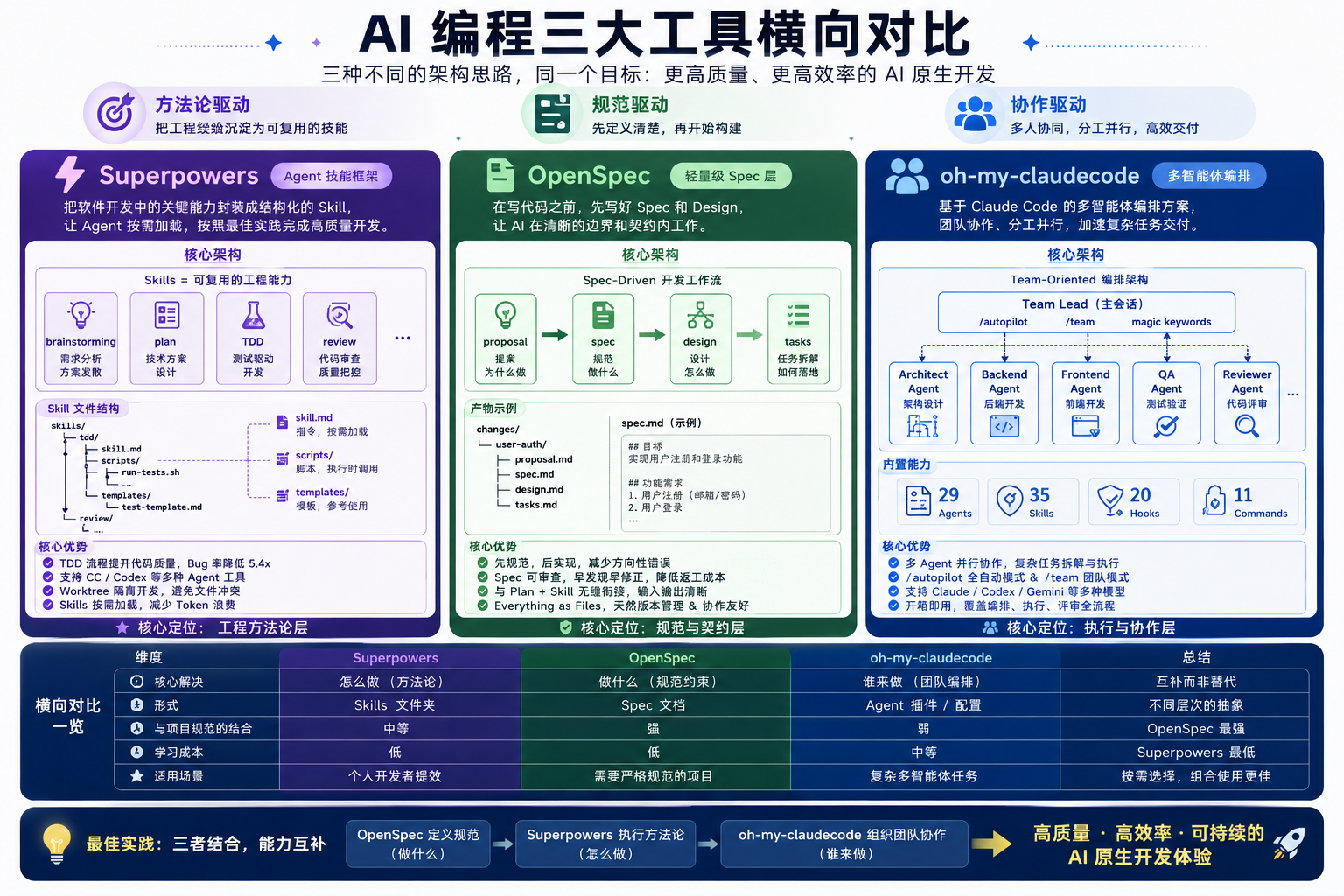
3.1 Superpowers — Agent 技能框架
obra/superpowers: An agentic skills framework & software development methodology that works.(github 206k)
Superpowers 是一套 Agentic Skills 框架和软件开发方法论。它的核心思想是:把软件开发中的关键能力封装成结构化的 Skill 文件夹,让 Agent 按需加载。
Superpowers 核心理念:┌─────────────────────────────────────────────┐│ ││ brainstorming → 需求分析和方案发散 ││ plan → 技术方案设计 ││ TDD → 测试驱动开发 ││ review → 代码审查 ││ ││ 每个 Skill = 一个文件夹 ││ ├── skill.md (指令,按需加载) ││ ├── scripts/ (脚本,执行时调用) ││ └── templates/ (模板,参考使用) ││ │└─────────────────────────────────────────────┘它的核心价值是:
- ✅ 通过 [[TDD测试驱动开发方法完全指南|TDD 流程]]提升代码质量,先写测试,再写业务代码,让测试驱动代码设计
- ✅ 支持 CC/Codex 等多种 Agent 工具
- ✅ 利用 [[Git Worktree完全指南|Worktree]] 实现隔离开发,避免文件冲突
- ✅ Skills 按需加载,减少 Token 浪费
但 Superpowers 更偏向方法论层面,它告诉你”应该怎么做”,但在”怎么管理多个任务的状态”、“怎么跨会话保持上下文”这些工程问题上,还需要更重的框架。
3.2 [[OpenSpec]] — 轻量级 Spec 层
Fission-AI/OpenSpec: Spec-driven development (SDD) for AI coding assistants.(github 50.6k)
OpenSpec 是一个专为 AI 设计的轻量级 Spec 层。它的核心理念是:在写代码之前,先写 Spec 和 Design。
OpenSpec 工作流: proposal → spec → design → tasks (提案) (规范) (设计) (任务拆解)关键设计:
- 先规范,后实现:强制 Agent 在动手前先明确边界和契约
- Spec 可审查:人类可以在 Spec 阶段发现方向性错误,比代码写好再改成本低得多
- Plan + Skill 联动:Spec 产物可以直接喂给后续的 Plan 和 Skill
OpenSpec 解决了”AI 乱写”的问题,但它更偏向文档层面的约束,缺少对执行过程的状态管理和上下文注入。
3.3 oh-my-claudecode — 多智能体编排
Yeachan-Heo/oh-my-claudecode: Teams-first Multi-agent orchestration for Claude Code(github 34.8k)
oh-my-claudecode 是一套基于 Claude Code 的 Multi-agent 编排方案,核心理念是 “teams-first, zero learning curve”。
oh-my-claudecode 架构: ┌──────────────────────────────────────┐ │ Team Lead (主会话) │ │ /autopilot /team magic keywords │ └──────────────┬───────────────────────┘ │ ┌───────────┼───────────┬───────────┐ ▼ ▼ ▼ ▼ Agent 1 Agent 2 Agent 3 Agent 4 (架构) (后端) (前端) (测试)核心亮点:
- 29 个 Agent、35 个 Skills、20 个 Hooks、11 个 Commands
- 支持 Claude、Codex、Gemini 等多种模型
/autopilot全自动模式 和/team团队模式- 作为 Claude Code Plugin 运行
它的优势是开箱即用的 Agent 团队能力,但缺点也比较明显:定制成本高,和项目规范的结合不够紧密。
3.4 三个工具的定位对比
| 维度 | Superpowers | OpenSpec | oh-my-claudecode |
|---|---|---|---|
| 核心解决 | ”怎么做”的方法论 | ”做什么”的规范约束 | ”谁来做”的团队编排 |
| 形式 | Skills 文件夹 | Spec 文档 | Agent 插件 |
| 与项目规范的结合 | 中等 | 强 | 弱 |
| 学习成本 | 低 | 低 | 中等 |
| 适用场景 | 个人开发者提效 | 需要严格规范的项目 | 复杂多智能体任务 |
而 Trellis 的设计思路,是把这三个方向整合到一个统一的框架里——既有 Spec 的规范能力,又有 Task 的任务管理,还有 JSONL 的上下文注入,以及 Hooks 的自动化触发。
4. Trellis 是什么
Trellis(GitHub: mindfold-ai/Trellis)是一个 AI Agent 的 “Agent Harness”(智能体驾驭框架)。它不替代 Claude Code 或 Cursor,而是在它们之上叠加一套结构化的治理层。
它的设计目标是解决三个核心痛点:
┌─────────────────────────────────────────────────────────────┐│ Trellis 解决的三个痛点 │├─────────────────────────────────────────────────────────────┤│ ││ 痛点 1:Session Death(会话死亡) ││ ├── 表现:长会话上下文塞满,AI 表现退化 ││ └── Trellis 方案:JSONL 上下文注入 + Journal 记录 + 任务隔离 ││ ││ 痛点 2:规范漂移(Spec Drift) ││ ├── 表现:每个会话 AI 的行为不一致,编码风格变来变去 ││ └── Trellis 方案:.trellis/spec/ 作为唯一真相源,每次会话自动注入 ││ ││ 痛点 3:知识流失(Knowledge Loss) ││ ├── 表现:Bug 修了又犯,经验无法沉淀 ││ └── Trellis 方案:/update-spec 持续沉淀 + /break-loop 根因分析 ││ │└─────────────────────────────────────────────────────────────┘5. Trellis 核心设计
5.1 整体架构
Trellis 的架构由三层组成,每一层解决一类问题:
┌────────────────────────────────────────────────────────────┐│ Trellis 三层架构 │├────────────────────────────────────────────────────────────┤│ ││ ┌──────────────────────────────────────────────────────┐ ││ │ Layer 1: Spec(规范层) │ ││ │ .trellis/spec/ │ ││ │ ├── shared/ # 跨层共享规范 │ ││ │ │ ├── index.md # 编码规范总览 │ ││ │ │ ├── cross-layer-thinking-guide.md │ ││ │ │ └── code-reuse-thinking-guide.md │ ││ │ ├── backend/ # 后端规范 │ ││ │ │ ├── index.md │ ││ │ │ ├── database-guidelines.md │ ││ │ │ ├── error-handling.md │ ││ │ │ ├── logging-guidelines.md │ ││ │ │ ├── api-module.md │ ││ │ │ └── quality-guidelines.md │ ││ │ └── frontend/ # 前端规范(如有) │ ││ │ 作用:定义"代码应该写成什么样" │ ││ └──────────────────────────────────────────────────────┘ ││ ││ ┌──────────────────────────────────────────────────────┐ ││ │ Layer 2: Task(任务层) │ ││ │ .trellis/tasks/ │ ││ │ ├── task.json # 任务元数据(状态、负责人、分支) │ ││ │ ├── prd.md # 需求文档 │ ││ │ ├── implement.jsonl # 实现阶段的上下文文件列表 │ ││ │ ├── check.jsonl # 检查阶段的上下文文件列表 │ ││ │ └── debug.jsonl # 调试阶段的上下文文件列表 │ ││ │ 作用:管理"当前在做什么、做到哪了、还需要什么上下文" │ ││ └──────────────────────────────────────────────────────┘ ││ ││ ┌──────────────────────────────────────────────────────┐ ││ │ Layer 3: Workspace(工作区层) │ ││ │ .trellis/workspace/ │ ││ │ └── {developer}/ │ ││ │ ├── journal-1.md # 工作日志(记录每次会话) │ ││ │ ├── journal-2.md │ ││ │ └── ... │ ││ │ 作用:记录"每次会话做了什么、学到了什么" │ ││ └──────────────────────────────────────────────────────┘ ││ │└────────────────────────────────────────────────────────────┘5.2 Spec 系统:把规范变成 AI 可执行的知识
Spec 是 Trellis 最核心的设计。它本质上是一套结构化的 Markdown 文档,存放在 .trellis/spec/ 目录下。但它的关键不在于”写了文档”,而在于文档如何被 AI 消费。
Spec 的三个层次
| 层次 | 目录 | 内容 | 举例 |
|---|---|---|---|
| 共享层 | shared/ | 所有技术栈通用的规范 | 目录结构、命名规范、Git 工作流 |
| 技术栈层 | backend/ / frontend/ | 特定技术栈的规范 | DAO 层写法、错误处理模式、组件规范 |
| 引导层 | guides/ | 跨层思维指南 | 跨层数据流思考、代码复用决策树 |
Spec 是如何被注入的
这是 Trellis 和 “写个 CLAUDE.md” 的本质区别:
传统方式(CLAUDE.md): 启动会话 → AI 读取 CLAUDE.md → 开始工作 问题:一个文件塞所有规范,Token 浪费,针对性弱
Trellis 方式(JSONL 上下文注入): 启动会话 → Hook 触发 → 根据任务类型选择 JSONL → 只注入当前阶段需要的 Spec 文件 → 开始工作
不同阶段注入不同 Spec: ├── implement 阶段:注入 implement.jsonl(编码规范 + 架构指南) ├── check 阶段:注入 check.jsonl(质量规范 + 检查清单) └── debug 阶段:注入 debug.jsonl(Spec + 上次 check 报告)这就是渐进式上下文注入——不把全部规范一次性塞给 AI,而是根据当前阶段按需加载。Token 更省,上下文更干净,AI 注意力更集中。
5.3 Task 系统:把任务变成可追踪的状态机
Trellis 的 Task 系统用 task.json 定义任务的完整生命周期:
{ "id": "02-27-user-login", "name": "user-login", "title": "用户登录功能", "description": "实现基于 JWT 的用户登录和 token 刷新", "status": "in_progress", "dev_type": "backend", "scope": "auth", "priority": "P1", "creator": "wcxian", "assignee": "wcxian", "branch": "feature/user-login", "base_branch": "main", "subtasks": [], "relatedFiles": [], "next_action": [ { "phase": 1, "action": "implement" }, { "phase": 2, "action": "check" }, { "phase": 3, "action": "finish" }, { "phase": 4, "action": "create-pr" } ]}Task 有四个状态,每个状态对应不同的自动化行为:
┌─────────────┐ │ Created │ ← task.py create │ (已创建) │ after_create hook └──────┬──────┘ │ ▼ ┌─────────────────┐ │ In Progress │ ← task.py start │ (进行中) │ after_start hook │ │ 自动创建 Git Worktree │ • Phase 1 │ 自动创建 Work Journal │ implement │ JSONL 上下文注入 │ • Phase 2 │ │ check │ └────────┬────────┘ │ ▼ ┌─────────────────┐ │ Finished │ ← /finish-work │ (已完成) │ after_finish hook │ │ AI Code Review │ │ Spec 合规检查 └────────┬────────┘ │ ▼ ┌─────────────────┐ │ Archived │ ← /record-session │ (已归档) │ after_archive hook │ │ 知识沉淀 + 会话存档 └─────────────────┘5.4 JSONL 上下文注入:按需喂给 AI 的知识
这是 Trellis 最精妙的设计之一。JSONL(JSON Lines)文件定义了每个阶段 AI 需要读取哪些文件:
implement.jsonl(实现阶段):
{"file": ".trellis/workflow.md", "reason": "Project workflow and conventions"}{"file": ".trellis/spec/shared/index.md", "reason": "Shared coding standards"}{"file": ".trellis/spec/backend/index.md", "reason": "Backend development guide"}{"file": ".trellis/spec/backend/api-module.md", "reason": "API module conventions"}{"file": ".trellis/spec/backend/quality.md", "reason": "Code quality requirements"}check.jsonl(检查阶段):
{"file": ".claude/commands/trellis/finish-work.md", "reason": "Finish work checklist"}{"file": ".trellis/spec/shared/index.md", "reason": "Shared coding standards"}{"file": ".claude/commands/trellis/check-backend.md", "reason": "Backend check spec"}设计要点:
file:文件路径,可以是文件或目录reason:为什么需要这个文件(帮助 AI 理解上下文意图)type:"file"或"directory"(目录最多加载 20 个 .md 文件)completion markers:标记哪些内容已完成(避免重复注入)
这个设计的精妙之处在于:它不是把所有知识一次性灌给 AI,而是根据当前阶段,精准投喂最相关的信息。 这就解决了”上下文膨胀”和”注意力稀释”的问题。
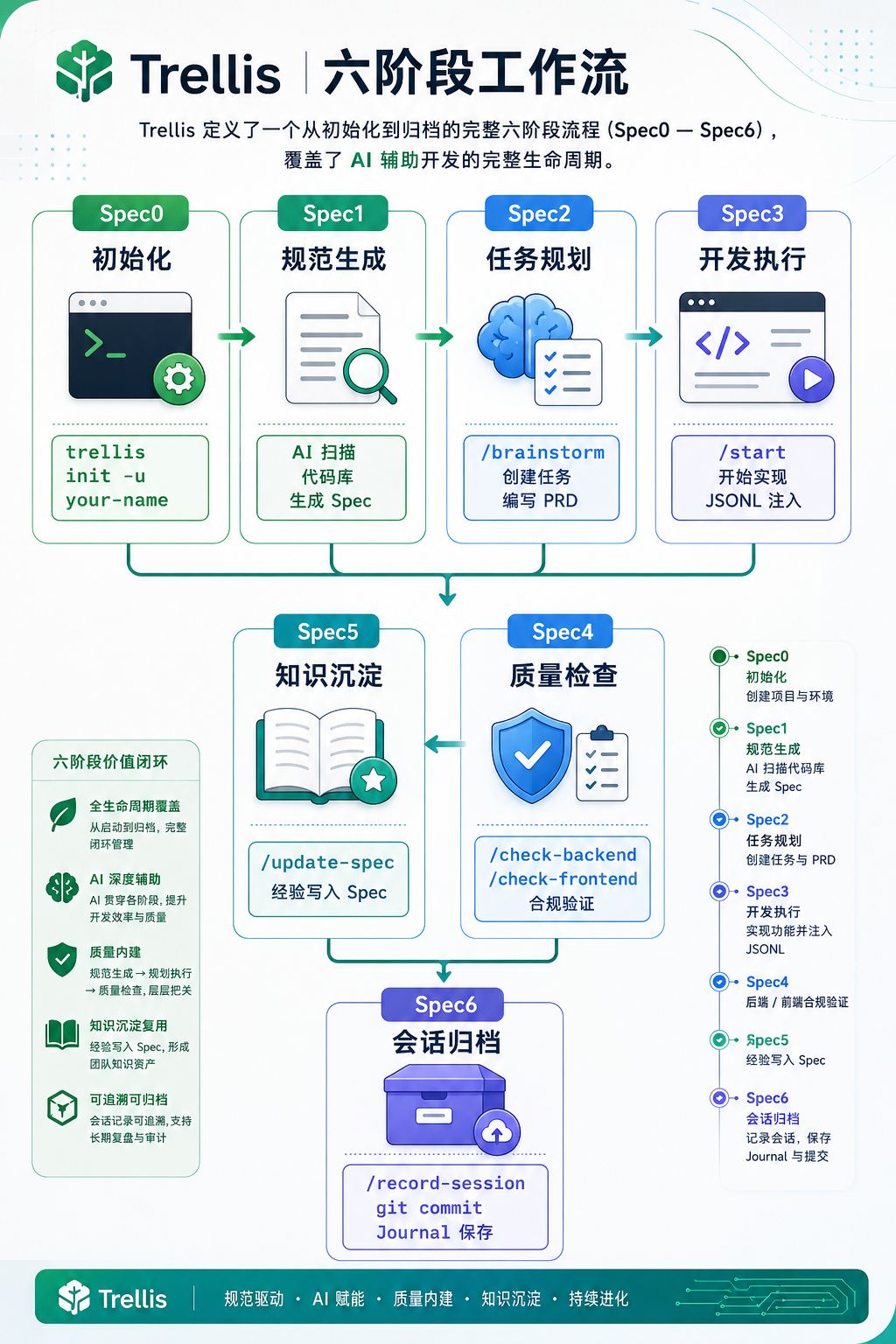
6. Trellis 六阶段工作流
Trellis 定义了一个从初始化到归档的完整六阶段流程(Spec0 — Spec6),覆盖了 AI 辅助开发的完整生命周期。
7. 将 Trellis 接入 Spring Boot 项目
光讲理论不够,这边我走一遍完整的接入流程。
7.1 初始化 Trellis
cd kuaijintrellis init -u wcxian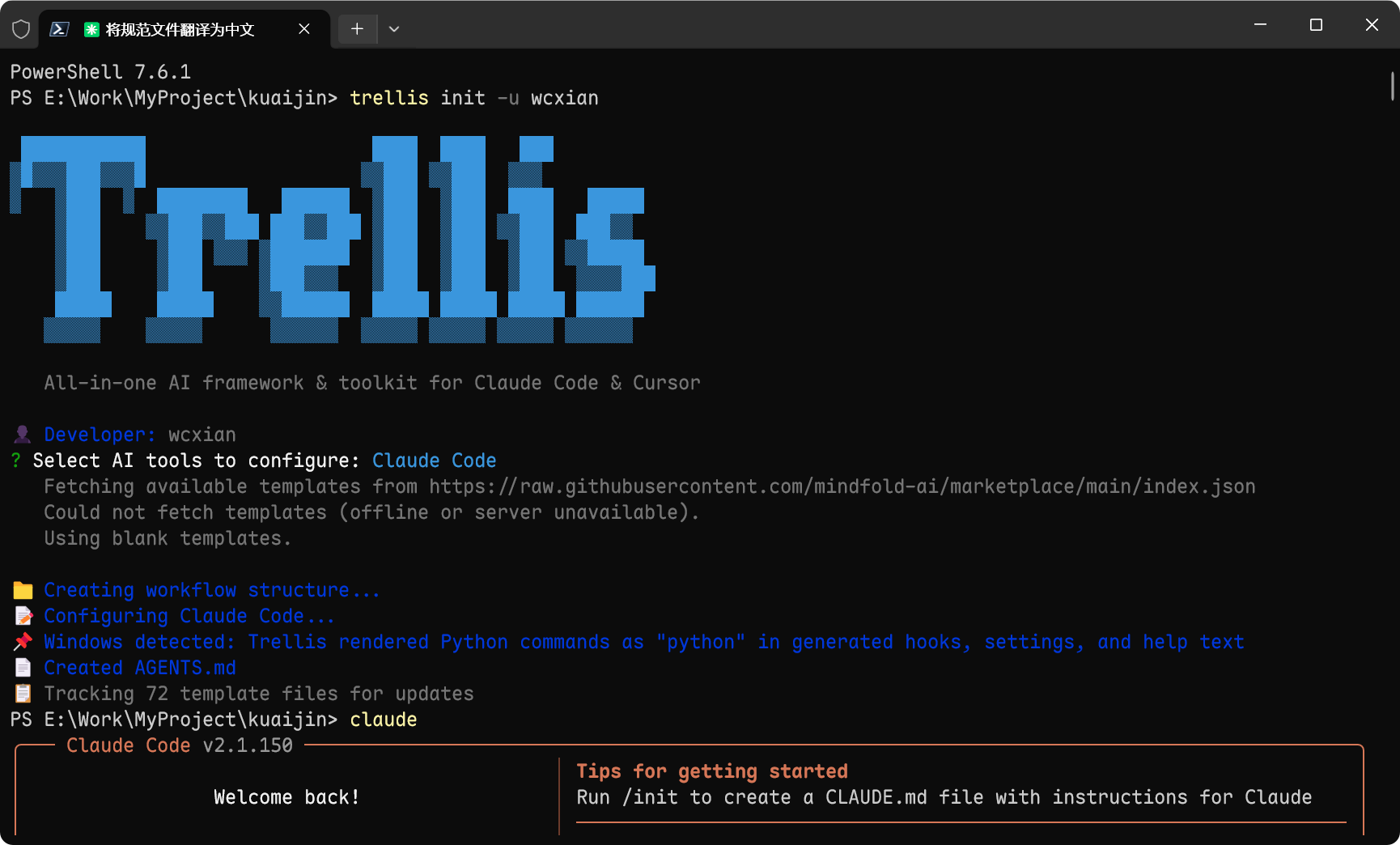
执行后目录变化:
hot-news/├── .trellis/ # 新增│ ├── spec/│ │ ├── shared/│ │ │ └── index.md│ │ ├── backend/│ │ │ └── index.md│ │ └── guides/│ │ └── index.md│ ├── tasks/│ ├── workspace/│ │ └── wcxian/│ │ └── journal-1.md│ └── workflow.md├── .claude/ # 新增(如果使用 Claude Code)│ └── commands/trellis/├── src/ # 原有代码不变└── pom.xml7.2 生成后端 Spec
在 Claude Code 中:
/trellis:continueAI 会读取你的代码,分析现有模式,生成对应的规范。比如它发现你的项目用 @RestController + @RequestMapping,就会在 api-module.md 里写:
## Controller 层规范- 使用 @RestController + @RequestMapping 注解- 统一返回 Result<T> 包装类- API 路径使用 kebab-case:/api/v1/hot-news- 参数校验使用 @Valid + BindingResult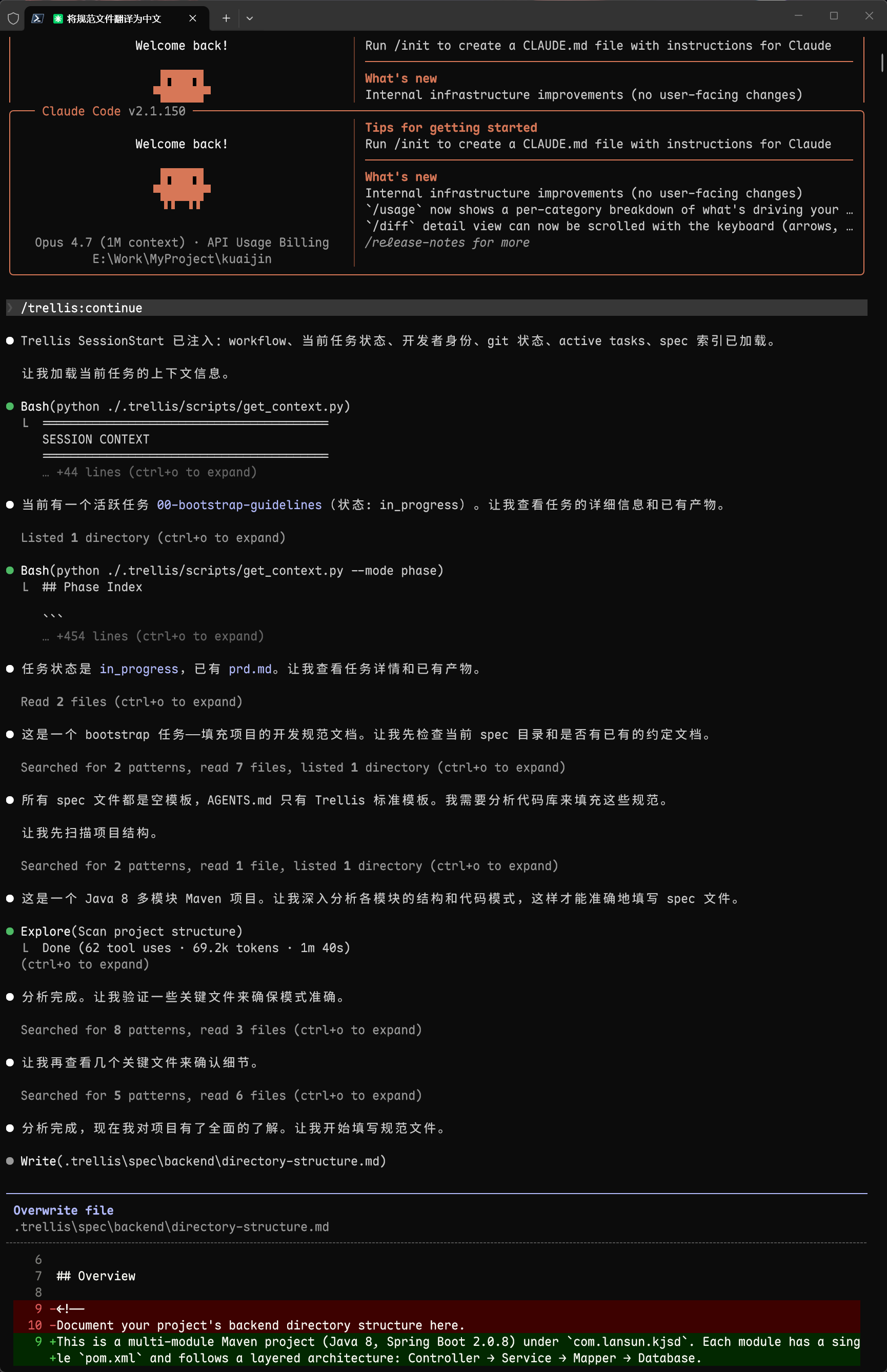
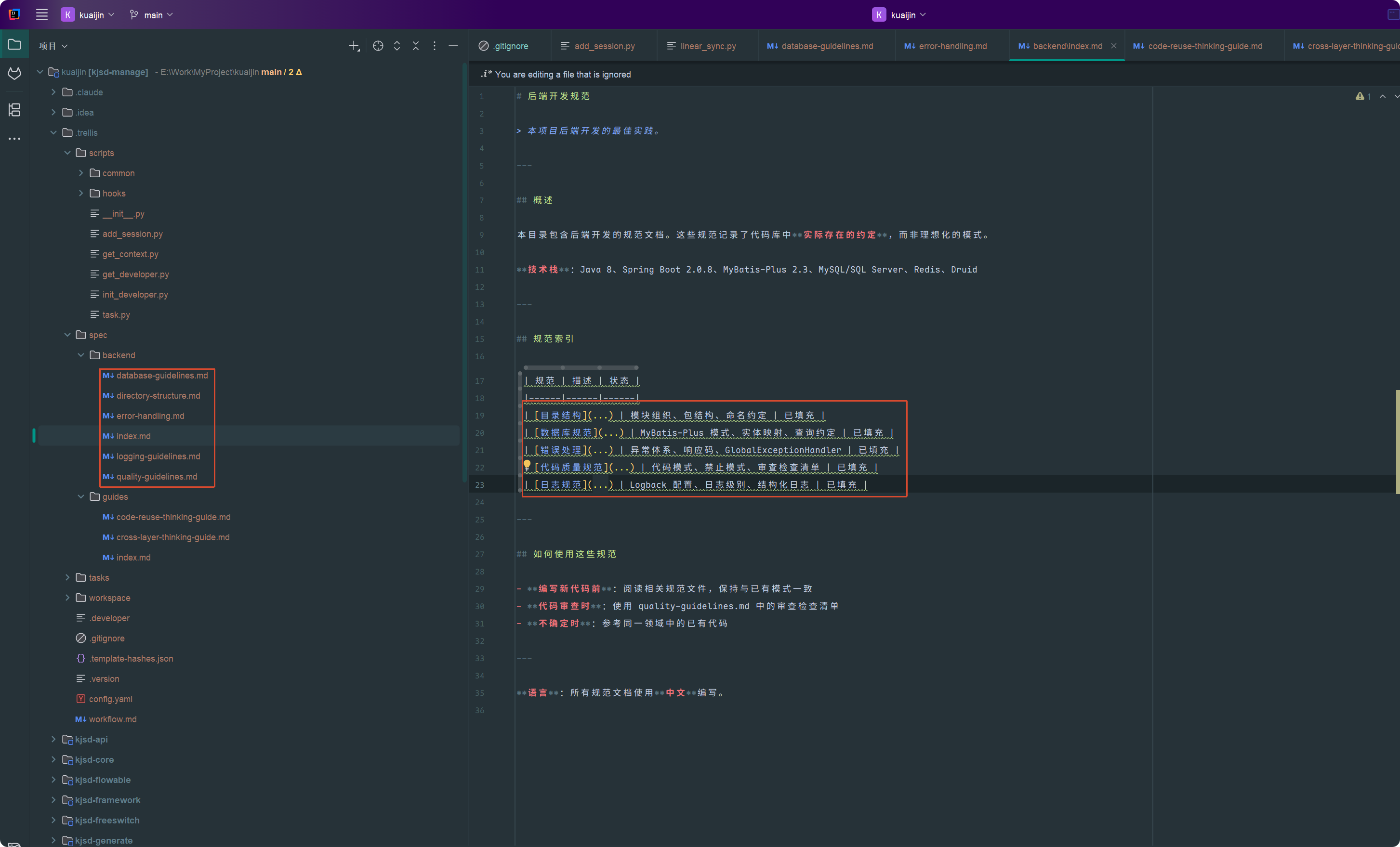
后端开发规范汇总版
7.3 创建任务
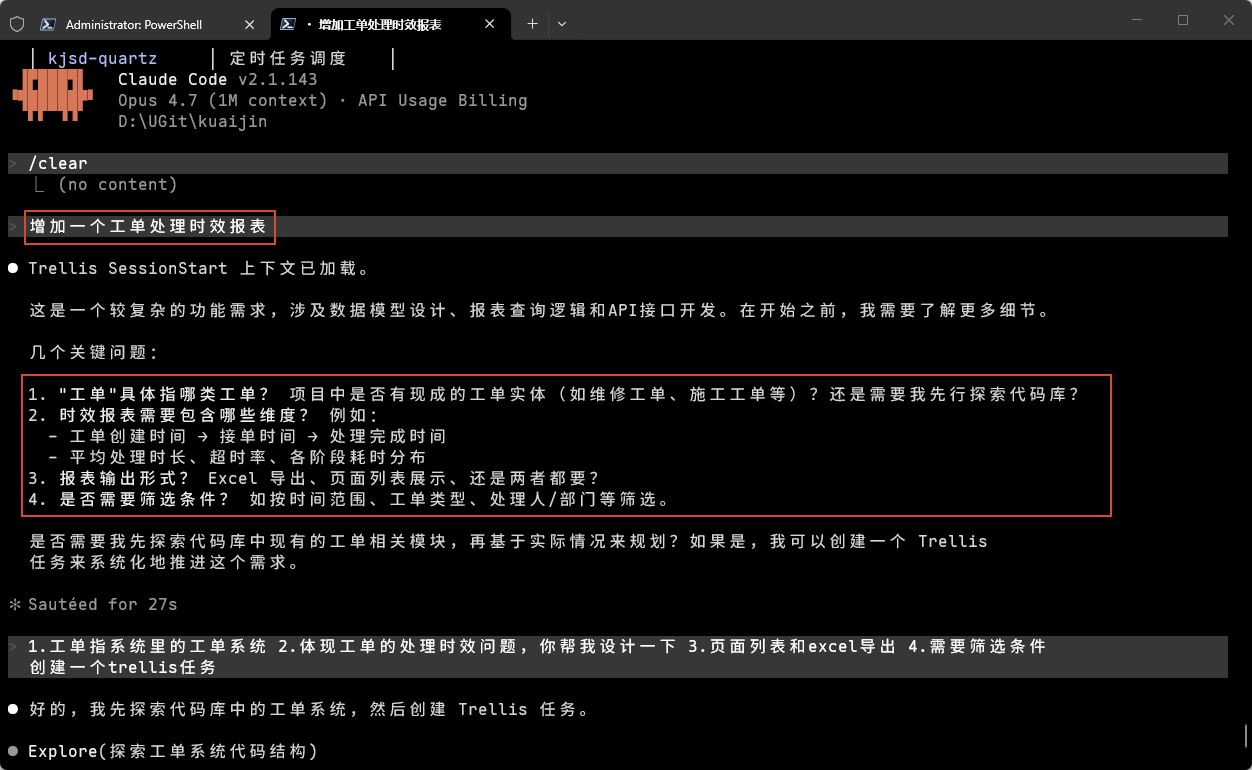
现在开始做第一个正式的功能。比如”增加一个工单处理时效报表”:
AI 会和你讨论需求细节,最终生成:
prd.md:完整需求文档task.json:任务元数据implement.jsonl:实现阶段上下文注入列表
输入需求
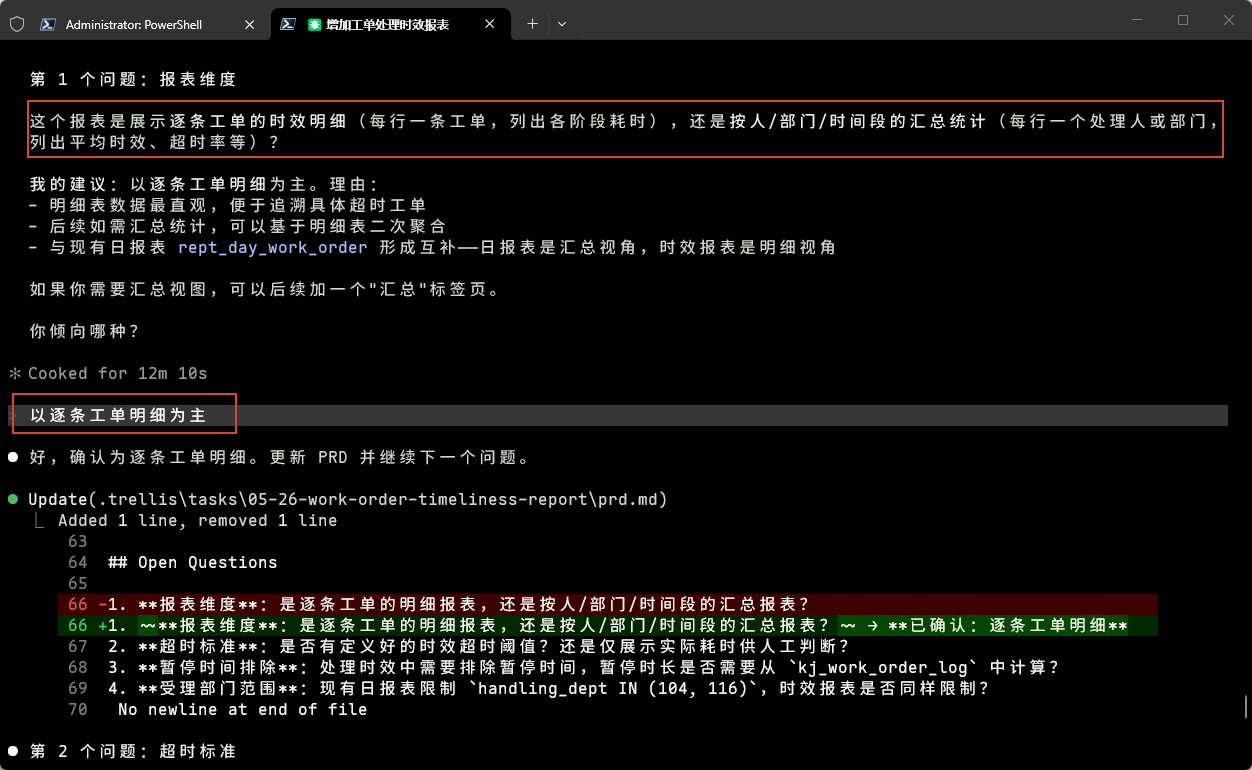
确认需求
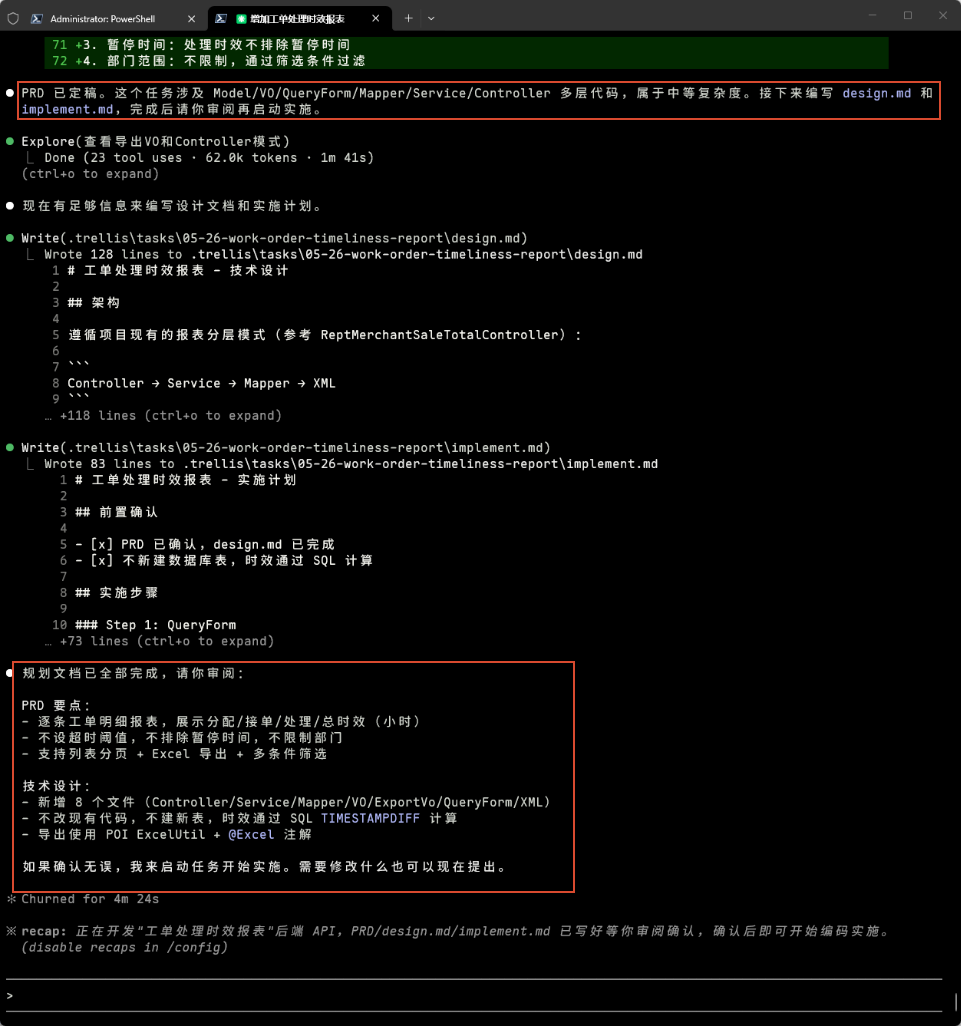
编写design.md 和 implement.md
7.4 启动开发
此时 Trellis 会自动:
- 在 Git Worktree 中创建
feature/zhihu-hotlist-crawler分支 - 在 Claude Code 会话中注入
implement.jsonl定义的所有 Spec 文件 - 创建
journal-2.md开始记录本次会话
不需要再重复说”请用 MyBatis-Plus 不要用 JPA”、“日志请用 Slf4j”、“返回格式用 Result
7.5 质量检查
编码完成后:
/check-backendAI 会逐项检查:
- ✅ 是否使用了 Spec 定义的目录结构
- ✅ Mapper 是否遵循了 database-guidelines
- ✅ 异常处理是否用了统一的 GlobalExceptionHandler
- ✅ 日志格式是否符合规范
- ✅ API 返回格式是否用了 Result
如果发现问题,AI 会直接修复,然后重新检查,直到全部通过。
7.6 归档
功能完成且检查通过后:
/finish-work # 完成工作,触发 after_finish hooks/record-session # 归档会话,生成 Journal8. Trellis 的 /break-loop
假设我们在上线后发现一个 Bug:定时任务偶尔会重复采集同一条数据。
8.1 普通修复流程
没有 Trellis 的情况下,修复流程可能是这样:
"帮我查一下为什么定时任务会重复采集数据"→ AI 分析代码,发现缺少分布式锁→ 加一把 Redis 分布式锁→ 提交,完事问题在于:下次做其他定时任务时,还是会忘记加锁。
8.2 Trellis 的 /break-loop 流程
/break-loopAI 会进行根因分析:
根因类别:并发控制缺失问题表现:定时任务在分布式环境下重复执行为什么之前的修复失败了: - 第一次修复:增加了唯一索引 → 不够,因为采集时间不同所以索引不冲突 - 第二次修复:增加了时间窗口判断 → 不够,因为多实例同时执行时窗口判断也同时通过根本原因:没有在分布式层面做互斥控制
预防机制: 1. 在 database-guidelines.md 中增加"定时任务必须使用分布式锁" 2. 在 quality-guidelines.md 中增加"定时任务检查清单" 3. 提供一个分布式锁的参考实现模板然后 AI 会:
- 修复代码(加上 Redis 分布式锁)
- 更新
database-guidelines.md,加入定时任务的分布式锁规范 - 更新
quality-guidelines.md,加入定时任务 Code Review 检查项
## 新增:定时任务规范(database-guidelines.md)
### 分布式锁要求所有定时任务必须使用分布式锁(Redis/Redisson),防止多实例重复执行:
@Scheduled(cron = "0 */30 * * * ?")public void crawlHotList() { RLock lock = redissonClient.getLock("lock:zhihu-crawl"); if (lock.tryLock(0, 25, TimeUnit.MINUTES)) { try { // 采集逻辑 } finally { lock.unlock(); } }}这就是从”修 Bug”到”防 Bug”的转变。 Trellis 让每次 Bug 修复都是一次知识沉淀,而不是一次性的救火。
9. 优势与局限
9.1 优势
| 优势 | 说明 |
|---|---|
| 上下文管理精准 | JSONL 按阶段注入,不做无差别的全量上下文轰炸 |
| 规范可持续沉淀 | Spec 不是一次性文档,而是持续更新的”活知识库” |
| 任务状态可追踪 | Created → In Progress → Finished → Archived,每个阶段都有自动化行为 |
| Worktree 天然隔离 | 每个任务独立分支,避免文件冲突,适合多人 + 多 Agent 协作 |
| 知识不会流失 | Journal + /update-spec + /break-loop 三重机制确保经验沉淀 |
| Hooks 自动化 | Session Start / Before Dev / After Finish 等钩子自动触发上下文注入 |
| 不绑定特定工具 | 支持 Claude Code、Cursor、Codex、OpenCode |
| 渐进式采用 | 可以先只用 Spec,再逐步启用 Task 和 Worktree |
9.2 局限
| 局限 | 说明 | 缓解方式 |
|---|---|---|
| 学习成本 | 六阶段流程 + 多套 JSONL 文件,新人需要适应 | 跟着 /trellis-onboard 走一遍 |
| 初始投入 | 需要花时间写 Spec,不是开箱即用 | Spec1 阶段的 AI 自动扫描能大幅降低负担 |
| Spec 维护成本 | 项目演进后 Spec 需要同步更新 | 把 /update-spec 作为日常工作流的一部分 |
| 小任务收益低 | 改一行配置也走完整流程是浪费 | 小修小改用”跳过 Trellis”模式 |
| 对 AI 能力有要求 | Spec 质量依赖于 AI 的代码理解和文档生成能力 | 关键 Spec 需要人工 review |
10. Trellis 与同类方案的对比
| 维度 | CLAUDE.md | OpenSpec | Superpowers | oh-my-claudecode | Trellis |
|---|---|---|---|---|---|
| 规范管理 | 单文件 | 多文件 Spec | Skills 文件夹 | 弱 | 多文件 + 分层 + JSONL 注入 |
| 任务状态 | 无 | 无 | 无 | 弱 | 四状态机 + 自动化 Hooks |
| 上下文注入 | 全量 | 手动 | 按需(Skills) | 无 | 分阶段 JSONL 注入 |
| Worktree 隔离 | 无 | 无 | 有 | 无 | 有 |
| 经验沉淀 | 无 | 有 | 无 | 无 | 三重机制 |
| 多 Agent 支持 | 无 | 无 | 弱 | 强 | Task 级别隔离 |
| 工具兼容 | Claude Code | 不限 | CC/Codex | Claude Code | CC/Cursor/Codex/OpenCode |
Trellis 的定位很明确:它不是一个”更强的 Prompt 技巧”,而是一套”AI 时代的工程治理框架”。
11. 总结
从 Harness Engineering 到 Trellis,本质上是在回答一个问题:
当 AI 编程从”辅助”走向”主力”时,工程治理应该长什么样?
我的答案是三个关键词:
- 结构化:不是把知识写进一个越来越长的 CLAUDE.md,而是分层、分阶段、按需注入
- 可沉淀:每一次开发、每一个 Bug、每一次 Review,都是知识积累的机会,不能让它流失
- 可复现:换一个会话、换一个人、换一个模型,输出质量应该保持一致
Trellis 不是银弹。它需要投入时间去设置 Spec,需要纪律去维护规范,需要在”速度”和”规范性”之间做权衡。但如果你在做的是一个需要长期维护、多人协作的项目,这套投入是值得的。
毕竟,AI 编程的下半场,比拼的不是谁用的模型更强,而是谁把模型驾驭得更好。
AI Coding 能力 = 模型能力 × Harness 质量
模型能力在飞速提升,但 Harness 质量——这个乘数因子—— 决定了你最终能从中榨出多少价值。参考资料
Anthropic Engineering:How we built our multi-agent research system
Claude Code Agent Teams 多智能体协作实战
Superpowers — Agentic Skills Framework
OpenSpec — Spec-driven development for AI